Grep and RegEx One-Liners
GREP, short for Global Regular Expression Print, is a command-line utility used in Unix, Linux, and other Unix-like operating systems. It searches for text patterns or regular expressions within files and directories, enabling users to locate specific strings or patterns of characters efficiently.
Regular Expressions (Regex or Regexp) are sequences of characters that form a search pattern. They’re employed in various programming languages and tools, including GREP, to perform intricate searches, manipulations, and validations within text. Regex provides a flexible way to define patterns, allowing for complex and specific string matching, substitution, or extraction.
Combining the power of GREP with Regex offers a robust and versatile method to search for, match, and manipulate text data, enabling users to perform advanced text processing and analysis efficiently. Both GREP and Regex play crucial roles in tasks like data extraction, text processing, file manipulation, and more, contributing significantly to the efficiency of developers, administrators, and data analysts in handling textual information.
Type of grep
grep = grep -G # Basic Regular Expression (BRE)
fgrep = grep -F # fixed text, ignoring meta-characters
egrep = grep -E # Extended Regular Expression (ERE)
pgrep = grep -P # Perl Compatible Regular Expressions (PCRE)
rgrep = grep -r # recursiveGrep and count the number of empty lines
grep -c "^$"Here, the ^ character matches the beginning of a line, and the $ character matches the end of a line. So, ^$ matches an empty line.
The -c the option counts the number of matching lines rather than displaying the lines themselves.
Replace filename With the file’s name, you want to search for empty lines.
Note that this command counts only completely empty lines. If a line contains any whitespace characters (such as spaces or tabs), it will not be considered empty by this command.
Grep and return only integer
grep -o '[0-9]*'
#or
grep -oP '\d*'Both grep -o '[0-9]*' and grep -oP '\d*' commands search for zero or more occurrences of digits in the input, and output each occurrence on a separate line using the -o option.
Here’s a breakdown of the commands:
grepis the command for searching text files for a specified pattern.-ooption tellsgrepto only output the matched parts of the line, rather than the entire line.[0-9]*is a regular expression pattern that matches zero or more occurrences of digits (0-9).\d*is a Perl-compatible regular expression pattern that matches zero or more occurrences of digits.
For example, if you have a file called example.txt with the following contents:
There are 5 apples and 3 oranges.
The number 42 is the answer to everything.
Running the command grep -o '[0-9]*' example.txt or grep -oP '\d*' example.txt would output:
5
3
42
This is because the regular expression pattern [0-9]* or \d* matches all occurrences of digits in the input, and the -o option tells grep to output each match on a separate line.
Grep integer with a certain number of digits (e.g. 3)
grep '[0-9]\{3\}'
# or
grep -E '[0-9]{3}'
# or
grep -P '\d{3}'Grep only IP address
grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'
# or
grep -Po '\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}'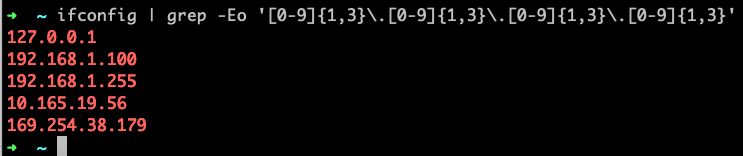
Grep whole word (e.g. ‘target’)
grep -w 'target'
#or using RE
grep '\btarget\b'
Grep returning lines before and after match (e.g. ‘bridge0’)
# return also 3 lines after match
grep -A 3 'bridge0'
# return also 3 lines before match
grep -B 3 'bridge0'
# return also 3 lines before and after match
grep -C 3 'bridge0'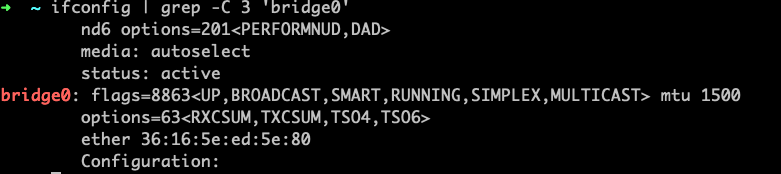
Grep string starting with (e.g. ‘S’)
grep -o 'S.*'Extract text between words (e.g. w1,w2)
grep -o -P '(?<=w1).*(?=w2)'Grep lines without word (e.g. ‘foo’)
grep -v foo filenameGrep lines not begin with string (e.g. #)
grep -v '^#' file.txtGrep variables with space within it (e.g. myvar=”some strings”)
grep "$myvar" filename
#remember to quote the variable!Grep only one/first match (e.g. ‘foo’)
grep -m 1 foo filenameGrep and return number of matching line(e.g. ‘foo’)
grep -c foo filenameCount occurrence (e.g. three times a line count three times)
grep -o foo filename |wc -lThe command grep -o foo filename | wc -l searches for the string foo in the file filename, displays each occurrence of foo on a separate line using the -o option, and then counts the number of lines using the wc command with the -l option. This gives you the total number of occurrences of foo in the file.
Here’s a breakdown of the command:
grepis the command for searching text files for a specified pattern.-ooption tellsgrepto only output the matched parts of the line, rather than the entire line.foois the pattern to search for.filenameis the name of the file to search in.|is the pipe symbol, which sends the output of thegrepcommand to thewccommand.wcis the command for counting words, lines, and characters in a file or stream.-loption tellswcto count the number of lines in the input.
For example, if you have a file called example.txt with the following contents:
This line contains foo, foo and foo
Another line containing foo foo
A line that does not match
Running the command grep -o foo example.txt | wc -l would output:
5
This is because there are 5 occurrences of the string foo in the file example.txt. The grep command outputs each occurrence of foo on a separate line, and the wc -l command counts the number of lines in the output, which is 5.
Case insensitive grep (e.g. ‘foo’/’fOO’/’Foo’)
grep -i "foo" filenameThe command grep -i "foo" filename searches for the string foo in the file filename and displays the matching lines, ignoring the case of the text.
Here’s a breakdown of the command:
grepis the command for searching text files for a specified pattern.-ioption tellsgrepto perform a case-insensitive search.foois the pattern to search for.filenameis the name of the file to search in.
For example, if you have a file called example.txt with the following contents:
This line contains Foo
Another line containing fOO
A line that does not match
Running the command grep -i "foo" example.txt would output:
This line contains Foo
Another line containing fOO
This is because both the first and second lines contain the string foo, even though the case of the text is different from the search term. The -i option tells grep to ignore the case of the text when searching for the pattern.
COLOR the match (e.g. ‘foo’)!
grep --color foo filenameThe command grep --color foo filename searches for the string foo in the file filename and displays the matching lines with the matching text highlighted in color.
Here’s a breakdown of the command:
grepis the command for searching text files for a specified pattern.--coloroption tellsgrepto highlight the matching text in color.foois the pattern to search for.filenameis the name of the file to search in.
For example, if you have a file called example.txt with the following contents:
This line contains foo
Another line containing foo
A line that does not match
Running the command grep --color foo example.txt would output:
This line contains \e[01;31mfoo\e[0m
Another line containing \e[01;31mfoo\e[0m
This is because the first two lines of the file contain the string foo somewhere in their contents. The matching text is highlighted in red, which is the default color used by grep. The \e[01;31m and \e[0m are escape sequences used by grep to specify the color of the highlighted text.
Grep searches all files in a directory(e.g. ‘foo’)
grep -R foo /path/to/directory
# or
grep -r foo /path/to/directoryThe command grep -R foo /path/to/directory or grep -r foo /path/to/directory (the lowercase “r” option is equivalent to the uppercase “R” option) searches for all files in the directory /path/to/directory and its subdirectories, that contain the string foo and displays the matching lines along with the name of the file where the match was found.
Here’s a breakdown of the command:
grepis the command for searching text files for a specified pattern.-Ror-roption tellsgrepto perform a recursive search through directories.foois the pattern to search for./path/to/directoryis the path to the directory to search in.
For example, if you have a directory called myfiles with the following files:
myfiles/
├── file1.txt
├── subdir/
│ ├── file2.txt
│ └── file3.txt
└── subdir2/
├── file4.txt
└── file5.txt
Running the command grep -R foo myfiles or grep -r foo myfiles would output:
myfiles/file1.txt:This line contains foo
myfiles/file1.txt:Another line containing foo
myfiles/subdir/file2.txt:Line containing foo in file2.txt
myfiles/subdir/file3.txt:Line containing foo in file3.txt
myfiles/subdir2/file4.txt:Line containing foo in file4.txt
myfiles/subdir2/file5.txt:Line containing foo in file5.txt
This is because all of the files contain the string foo somewhere in their contents. Note that the search is case-sensitive, so it will only match lines containing foo, not Foo or FOO. The output also shows the name of the file where the matching line was found, followed by the matching line itself.
Search all files in a directory, do not ouput the filenames (e.g. ‘foo’)
grep -rh foo /path/to/directoryThe command grep -rh foo /path/to/directory searches for all files in the directory /path/to/directory and its subdirectories, that contain the string foo and displays the matching lines without showing the name of the file where the match was found.
Here’s a breakdown of the command:
grepis the command for searching text files for a specified pattern.-roption tellsgrepto perform a recursive search through directories.-hoption tellsgrepnot to display the filename where the matching line was found.foois the pattern to search for./path/to/directoryis the path to the directory to search in.
For example, if you have a directory called myfiles with the following files:
myfiles/
├── file1.txt
├── subdir/
│ ├── file2.txt
│ └── file3.txt
└── subdir2/
├── file4.txt
└── file5.txt
Running the command grep -rh foo myfiles would output:
This line contains foo
Another line containing foo
Line containing foo in file2.txt
Line containing foo in file3.txt
Line containing foo in file4.txt
Line containing foo in file5.txt
This is because all of the files contain the string foo somewhere in their contents. Note that the search is case-sensitive, so it will only match lines containing foo, not Foo or FOO.
Search all files in a directory, and output ONLY the filenames with matches(e.g., ‘foo’)
grep -rl foo /path/to/directorythe command grep -rl foo /path/to/directory would search for all files in the directory /path/to/directory and its subdirectories that contain the string foo, and display the names of the matching files.
Here’s a breakdown of the command:
grepis the command for searching text files for a specified pattern.-roption tellsgrepto perform a recursive search through directories.-loption tellsgrepto display only the names of the files that match the pattern.foois the pattern to search for./path/to/directoryis the path to the directory to search in.
For example, if you have a directory called myfiles with the following files:
myfiles/
├── file1.txt
├── subdir/
│ ├── file2.txt
│ └── file3.txt
└── subdir2/
├── file4.txt
└── file5.txt
Running the command grep -rl foo myfiles would output:
myfiles/file1.txt
myfiles/subdir/file2.txt
myfiles/subdir/file3.txt
myfiles/subdir2/file4.txt
myfiles/subdir2/file5.txt
This is because all of the files contain the string foo somewhere in their contents. Note that the search is case-sensitive, so it will only match files containing foo, not Foo or FOO.
Grep OR (e.g. A or B or C or D)
grep 'A\|B\|C\|D'
The command grep 'A\|B\|C\|D' Search for lines in a file or input containing any characters ‘A,’ ‘B,’ ‘C,’ or ‘D’. The vertical bar | is used to separate the different characters to search for.
For example, if you have a file called example.txt with the following content:
Apple
Banana
Cherry
Date
Running the command grep 'A\|B\|C\|D' example.txt would output:
Apple
Banana
Cherry
Date
This is because all of the lines contain at least one of the specified characters. Note that the search is case-sensitive and will only match uppercase or lowercase letters.
Grep AND (e.g. A and B)
grep 'A.*B'Regex any single character (e.g. ACB or AEB)
grep 'A.B'Consider a file named example.txt with the following contents:
This is an example file.
It contains some AxB patterns, such as A1B, A#B, and A_B.
If we run the grep 'A.B' example.txt command, it will search for lines in the file that contain the letters “A” and “B” with any single character in between them. In this case, the pattern 'A.B' will match the following string in the file:
It contains some AxB patterns, such as A1B, A#B, and A_B.
This is because the pattern matches all occurrences of “A” followed by any single character followed by “B” in the line. Therefore, grep will output the entire line as a match.
Note that the period (.) in the pattern matches any single character, including spaces and special characters. So, the pattern will also match strings like “A B”, “A_B”, “A#B”, etc. The . is a wildcard character in regular expressions and can be very useful when searching for patterns that have some variability.
Regex with or without a certain character (e.g. color or colour)
grep 'colou\?r'Here’s what the command you provided does:
grep: The command itself.'colou\?r': This is the pattern thatgrepwill search for. It consists of two parts:colou: This matches the characters “colou” exactly.\?: This is a special character that matches the preceding character (in this case, the letter “u”) either zero or one times. So, the\?makes the “u” optional, allowing the pattern to match either “color” or “colour”.r: This matches the letter “r”.
So, in summary, the command searches for lines in a file that contain the words “color” or “colour”, with the “u” being optional. This can be useful when searching for variations in spelling or regional differences.
Grep all content of a fileA from fileB
grep -f fileA fileBHere’s what the command you provided does:
grep: The command itself.-f fileA: This option tellsgrepto read the search patterns fromfileAinstead of the command line. Each line infileAis treated as a separate pattern to search for.fileB: This is the file thatgrepwill search for the patterns in.
So, in summary, the command searches for each line in fileA in fileB. If a line in fileB contains any of the patterns in fileA, grep will output that line. This can be useful for finding lines that match a set of specific patterns, such as a list of keywords or regular expressions.
Grep a tab
grep $'\t'Here’s what the command you provided does:
grep: The command itself.$'\t': This is a bash-specific syntax that represents a tab character. The$before the single quotes indicates that this is a special shell parameter, and the\tinside the single quotes is replaced with a tab character before the command is executed.
So, in summary, the command searches for lines in a file that contain a tab character. The exact usage may depend on what file or input is being searched, as the command does not specify a file or input. For example, you might use this command to search for lines in a text file that have tab-separated values.
Grep variable from a variable
$echo "$long_str"|grep -q "$short_str"
if [ $? -eq 0 ]; then echo 'found'; fi
#grep -q will output 0 if match found
#remember to add space between []!This is a shell script that tests whether the variable $short_str is a substring of the variable $long_str. Here’s how it works:
echo "$long_str": This command outputs the value of the variable$long_str.grep -q "$short_str": This command searches for the value of the variable$short_strin the output of theechocommand. The-qoption tellsgrepto be quiet and not output anything; instead, it simply sets the exit code to 0 if a match is found, or 1 otherwise.if [ $? -eq 0 ]; then echo 'found'; fi: This is an if statement that tests the exit code of thegrepcommand. If the exit code is 0, then a match was found and the script outputs the message “found”. Otherwise, the script does nothing.
So, in summary, this shell script tests whether $short_str is a substring of $long_str, and outputs the message “found” if it is. The grep -q command is used to perform the substring search, and the if statement tests the exit code of the grep command to determine whether a match was found.
Grep strings between a bracket()
grep -oP '\(\K[^\)]+'Here’s what the command you provided does:
grep: The command itself.-o: This option tellsgrepto only output the matching part of the line, rather than the entire line.-P: This option enables Perl-compatible regular expressions, which allows for more powerful pattern matching.'\(\K[^\)]+': This is the pattern thatgrepwill search for. It consists of two parts:\(: This matches an opening parenthesis.\K: This is a special construct that tells the regular expression engine to “keep” everything that was matched before this point, but not include it in the final match. In other words,\Kresets the starting point of the match, effectively “forgetting” what came before it.[^\)]+: This matches one or more characters that are not a closing parenthesis.
So, in summary, the command searches for a pattern consisting of an opening parenthesis, followed by any number of non-parenthesis characters. However, the \K construct causes grep to “forget” about the opening parenthesis, so only the non-parenthesis characters are output. The -o option causes grep to only output this matched pattern, rather than the entire line on which the pattern occurs. The -P option enables the use of Perl-compatible regular expressions, which allows for more powerful pattern matching.
Grep number of characters with known strings in between(e.g. AAEL000001-RA)
grep -o -w "\w\{10\}\-R\w\{1\}"
# \w word character [0-9a-zA-Z_] \W not word characterHere’s what the command you provided does:
grep: The command itself.-o: This option tellsgrepto only output the matching part of the line rather than the entire line.-w: This option tellsgrepto only match whole words. For example, if the pattern iscat,grepwill match lines containingcatbut not lines containingcatapult."\w\{10\}\-R\w\{1\}": This is the pattern thatgrepwill search for. It consists of two parts:\w\{10\}: This matches any sequence of 10 word characters. Word characters include letters, digits, and underscores. The\{10\}specifies that the preceding character or character class (in this case,\w) must be matched exactly 10 times.\-R: This matches a hyphen (-) followed by an uppercaseR.\w\{1\}: This matches any single-word character.
So, in summary, the command searches for a pattern consisting of a sequence of 10-word characters, followed by a hyphen and an uppercase R, and then one more word character. The -o option causes grep to only output this matched pattern rather than the entire line on which the pattern occurs.
Skip directory (e.g. ‘foo’)
grep -d skip 'foo' /path/to/files/*Here’s what the command you provided does:
grep: The command itself.-d skip: This option tells grep to skip directories while searching for files. Ifgrepencounters a directory, it will not search its contents. Instead, it will move on to the next file.'foo': This is the pattern thatgrepwill search for. In this case,foois enclosed in single quotes to prevent the shell from interpreting it as a special character./path/to/files/*: This is the path to the directory wheregrepwill start its search. The asterisk*is a wildcard character that matches any file or directory name in that directory.
So, in summary, the command searches for the pattern ‘foo’ in all files in the directory /path/to/files/, but skips any directories it encounters.



7 Responses
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]
[…] Part 1 – How to use Grep and Regular Expressions (RegEx) […]